
この内容は、2023年4月、windowsでのものです。
ちなみにこのようなことをしなくても、
wiki40Bという、tensorflowのデータセットがあるようです。
これは単純にやってみたいということでやっています。
参考記事
wikipediaのデータからword2vecコーパスを作成する
仮想環境を使おう
実はwikiコーパス作りは、何度か挑戦していて、
ことごとく失敗しています・・・
そんなわけで、今回は仮想環境を使用します。
参考記事はAnacondaを使用しています。
私はAnacondaは使ってないので、
pipで環境を作りました。
そちらの挑戦記録は
に記載しています。よろしければどうぞ。
wikiデータのダウンロード
curlはwindowsでも使えるので参考記事そのまま。
curl https://dumps.wikimedia.org/jawiki/latest/jawiki-latest-pages-articles.xml.bz2 -o jawiki-latest-pages-articles.xml.bz2とても時間がかかります。
久々にシーツを取り換え洗濯し、掃除機をかけ
食料品の買い出しに行き、100均に寄り道しても
まだ、十分な時間です。
通信が途切れるのが怖くなければ、
裏でダウンロードしながらマインクラフトを楽しむのもよいでしょう。
データーの解凍
下準備
まだ入れていなければ、gitを入れといてくださいね。
windowsの場合はGUIでインストールできます。
WindowsにGitをインストールする手順(2023年04月更新)
wikiExtractorで解凍
まずは、wikiExtractorをインストールします。
ここで、gitが出てきますね。
pip install git+https://github.com/prokotg/wikiextractor※ 注意点
インストールの際、python3.11ではエラーが出るかもしれません。
私は、真っ赤な文字で思いっきりエラー出ました・・・
その場合はpython3.10の仮想環境をもう一つ作ります。
やり方はpython3.10を普通にexeファイルでインストールします。
Add Python PATHのチェックは入れてください。

(東京工業大学の画像借りちゃいました!)だから3.9なんです。
他のバージョンのpythonもアンインストールとかしません。
どちらか選んで使う感じです。
仮想環境の作り方ですが、
私の場合は
py -3.10 -m venv py310envで新しい仮想環境を作りました。アクティブ化するときも
.\py310env\Scripts\activateと名前をそろえてあげてください。
そして解凍。
うまくwikiExtractorがインストール出来たら
wikiデーターの解凍をします。
python -m wikiextractor.WikiExtractor jawiki-latest-pages-articles.xml.bz2解凍されたデーターは新しくできた、textというフォルダにあります。

わかち書きとファイルの統合
ここで、MeCabをインストール。
以前にもインストールしてはいますが、
(その時の記事。MeCabインストール)
仮想環境に改めてインストール。
(コマンドで仮想環境を有効化してそのままインストールの意味)
pip install mecab-python3MeCabはわかち書きに使用します。
参考では、pythonでプログラムを書いて
MeCabでわかち書きして、UTF-8で書き込み処理しています。
wiki1_wakati_gather.pyと題してあります。
そのままコピーしたら動かなかったので、
デバックしながら少し修正したのが下記です。
import glob
import logging
import os
import MeCab
if not os.path.exists("./wakati"): # ディレクトリが無かったら作成
os.mkdir("wakati")
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
logger = logging.getLogger(__name__)
tagger = MeCab.Tagger("-Owakati")
AllData = ''
Folders = glob.glob('text\*') # textディレクトリ内のフォルダを取得
start_num = 0 # 開始するフォルダの番号を指定
# 一度で実行する場合は0,途中で止まった後に再開するときはその番号
for FolderName in Folders[start_num+0:]:
files = glob.glob(f"{FolderName}\*") # フォルダの中身を取得
for file in files:
f = open(file, 'r', encoding='UTF-8') # 読み込むので"r",UTF-8を指定
data = f.read()
#AllData += data + '\n'
wakatiData = tagger.parse(data)
AllData += wakatiData + '\n'
logger.info(file)
f.close()
#wf = open(f'data/wiki_data_{FolderName[5:7]}.txt', 'w', encoding='UTF-8')
wf = open(f'wakati/wiki_data_{FolderName[5:7]}.txt', 'w', encoding='UTF-8')
wf.write(AllData)
wf.close
wf = open('wiki_data.txt', 'w', encoding='UTF-8')
wf.write(AllData)結果ですが、wakatiというフォルダが作成され、
その中にAAからなる分割ファイルがtxtで保存されています。

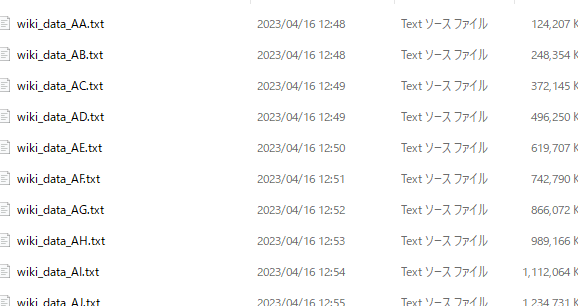
そしてwiki_data.txtというのが統合ファイルですね。

統合ファイルは大きすぎるので、
分割ファイルの中身を見てみます。

うまくいったようですね。
でもまだ文頭の<doc>やカッコなどが邪魔なんですね。
タグや記号の除去
こちらも参考から引用します。
以前の失敗は、このタグ消去で、
sedを使った処理が終わらなくて困っていました。
こちらはタグ消去にMeCabを使用していますね。
wiki2_remove_tag.pyと名づけてあります。
import re
import MeCab
f = open("wiki_data.txt", 'r', encoding='UTF-8')
data = f.read()
f.close()
# 最初にあるタグを消す
data = re.sub(r"<.*?>", r"", data)
# 半角記号削除
data = re.sub(r'[!"#$%&\'\\\\()*+,-./:;<=>?@[\\]^_`{|}~「」〔〕“”〈〉『』【】&*・()$#@。、?!`+¥%]', '', data)
# 全角記号削除
data = re.sub("[\uFF01-\uFF0F\uFF1A-\uFF20\uFF3B-\uFF40\uFF5B-\uFF65\u3000-\u303F]", '', data)
# print(data[0:10000])
#ファイルに書き込み
wf = open('wiki_tag_removed_data.txt', 'w', encoding='UTF-8')
wf.write(data)
wf.close()プログラムはすんなり通りました。データーの容量比較です。

下が不要なものを削除したファイル。かなり小さくなっています。
ついでにWord2Vec
参考ではWord2Vecでベクトル化までやっています。
私もやってみます。
Word2Vecが初めての方は私の挑戦記録
ChatGPTにWord2Vecを教えてもらったは参考にならないかしら?
こちらのプログラム名は、wiki3_make_vector.pyとしていますね。
参考と違う点は、参考ではファイル名を変更しているところ、
私は混乱を避けるために、もとのまま
wiki_tag_removed_data.txtとしています。
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus('./wiki_tag_removed_data.txt')
model = word2vec.Word2Vec(sentences, vector_size=200, min_count=20, window=15)
model.wv.save_word2vec_format("./wiki.model", binary=True)おたのしみの類似語検索
プログラム名は、ruiji_otanosimi.py としまして、
‘大谷’といえば?
from gensim.models import KeyedVectors
wv = KeyedVectors.load_word2vec_format('wiki.model', binary=True)
results = wv.most_similar(positive='大谷')
for result in results:
print(result)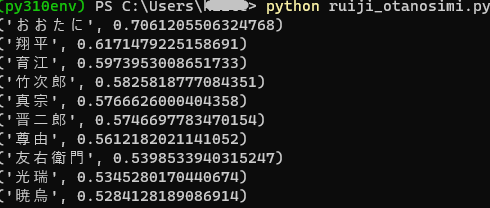
美人といえば?
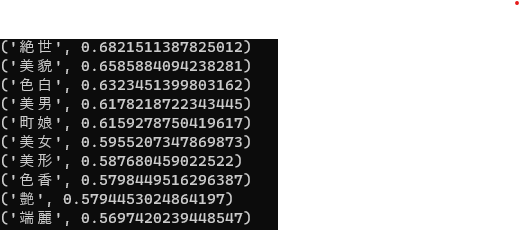
成功といえば?

といった感じになりました。
語句によっては、そもそもエラーになったりします。
さらに追及ですね。

