こちら2023年4月の内容です。
※ Word2Vecのインストールは
pip install gensimで、できます。
コードをネットで検索すると時間がかかります
と、いうわけでChatGPTに聞いてみました!”
“word2vecで、分かち書きした小説を解析するコードを教えて”
と質問してみました。
ChatGPTの答えはこんな感じ
Word2Vecは、単語を数値化する手法の1つで、自然言語処理の分野で広く使用されています。ここでは、Pythonのgensimライブラリを使用してWord2Vecを実装する方法を説明します。
- gensimライブラリをインストールします。
python
!pip install gensim- 分かち書きした小説のテキストファイルを準備します。テキストファイルには、スペースで区切られた単語のリストが含まれている必要があります。
the cat sat on the mat
the dog ran away
...- ファイルを読み込み、Word2Vec を学習させます。以下のようなコードを使用することができます。
from gensim.models import Word2Vec
# テキストファイルの読み込み
with open('text.txt', 'r', encoding='utf-8') as f:
sentences = [line.strip().split() for line in f]
# Word2Vecの学習
model = Word2Vec(sentences, size=100, window=5, min_count=5, workers=4)
size: 生成する滑らかの次元数window:対処前の金額min_count:学習に使用する最小単語出現数workers:使用するCPUコア数
- 学習されたWord2Vecモデルを使用して、単語の否定表現を取得することができます。
vector = model.wv['cat']以上の手順で、Word2Vecを用いて分かち書きした小説の解析を行うことができます。ただし、データセットのサイズやハイパーパラメータなどによって、結果が大きく変わります。
となりました。
親切なことに、なんとgensimのインストールから説明してくれました。
コードを試してみる
変更点はファイル名と、model = ~~の「size」の部分です。
調べたところ、最近の書き方は vector_size=~とするようです。
そしてmodelを保存するために、
model.save("word2vec.nekodearu.model")をつけて、
最後に「おわりました」と表示されるようにしました。
from gensim.models import Word2Vec
# テキストファイルの読み込み
with open('nekodearu_splitted.txt', 'r', encoding='utf-8') as f:
sentences = [line.strip().split() for line in f]
# Word2Vecの学習
model = Word2Vec(sentences, vector_size=200, window=5, min_count=5, workers=4)
# modelの保存
model.save("word2vec.nekodearu.model")
# 終了の確認
print("おわりました")結果確認
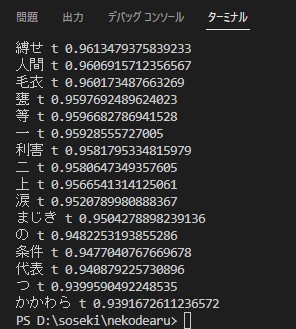
今回の元ネタは「吾輩は猫である」ですので、
「吾輩」に関連する言葉を20表示してみました。
from gensim.models import word2vec
model = word2vec.Word2Vec.load("word2vec.nekodearu.model")
results = model.wv.most_similar(positive="吾輩", topn=20)
for result in results:
print(result[0], 't', result[1])結果はこんな感じでした。