
こちら、令和5年4月、winsowsでの記事です。
形態素解析の記事は結構ありますので、
素人なりの着眼でちょこちょこ書いてみます。
解析にはMeCabを使用しました。前回MeCabインストール
青空文庫はもう有名ですね
素材は青空文庫から入手しました。
平均的日本語?
平均的日本語、小説、青空文庫、などと検索すると、
夏目漱石が出てきますね。私も漱石は好きなので、漱石をダウンロードしました。
青空文庫からダウンロードするのはZipファイルにしましょう。
私は、Dドライブにsosekiというフォルダーを作り、
作品をわかりやすい名前に変えて保存しました。
ここで、形態素解析するときのちょっとしたポイント。
- zipファイルは、「すべて展開」(解凍)して保存します。
- ファイルの名前を変更した時、中のtxtファイルの名前が
同じ変更にならないときがありますので確認を!
pythonとMeCabで解析してみます
コードに関しては、この方のコードを使用させていただきました。
もう変数まで一緒です。少し自分で考えなければいけないですね・・・
import re # 正規表現
import pickle # データの直列化
import MeCab
PATH = r"D:\soseki\nekodearu"
FILENAME = r"\nekodearu"
# テキストファイルの読み込み
file_r = PATH + FILENAME + ".txt"
with open(file_r) as f:
text = f.read()
# 前処理
text = re.split(r"\-{5,}", text)[2] # ハイフンより上を削除
text = re.split(r"底本:", text)[0] #「底本:」より下を削除
text = re.sub(r"[#8字下げ.*?中見出し]", "", text) # 中見出しを削除
text = re.sub("※", "", text) # 「※」を削除
text = re.sub(r"《.*?》", "", text) # 《...》を削除
text = re.sub(r"[.*?]", "", text) # [...]を削除
text = re.sub(r"(.*?)", "", text) # (...)を削除
text = re.sub(r"|", "", text) # 「|」を削除
text = re.sub("\n", "", text) # 改行を削除
text = re.sub(" [一二三四五六七八九十]+", "", text) # 漢数字を削除
text = re.sub(r"\u3000", "", text) # 全角スペースを削除
text = re.sub(r"。", "<period>", text) # 句点を<period>に
# 「」内のピリオドを句点に置き換え
pattern = re.compile("「.*?」") # 正規表現にコンパイル、形を変える
match_sents = pattern.findall(text) # パターンにあった全ての文字列をリストとして取得
for i, m_sent in enumerate(match_sents): # enumerateは列挙するの意
new_sent = m_sent.replace("<period>", "。") # replaceは置換
text = text.replace(m_sent, new_sent)
# ピリオドで分割
text_splitted = text.split("<period>")
# 空要素を取り除く
text_splitted = list(filter(None, text_splitted))
# 1文ずつ形態素解析
mecab = MeCab.Tagger("-Owakati")
for i in range(len(text_splitted)):
text_splitted[i] =mecab.parse(text_splitted[i]).split()
print(text_splitted) # 確認のため結果表示させてみる
# テキストファイルに書き込む
file_w = PATH + FILENAME + "_splitted.txt"
s = ""
with open(file_w, mode="w") as f:
for text in text_splitted:
s += " ".join(text) + "\n"
f.write(s)
# picle化
file_wb = PATH + FILENAME + ".pickle"
with open(file_wb, mode="wb") as f:
pickle.dump(text_splitted,f)
最初の「re」は正規表現をすることらしいです。
pickleてなんぞや?
Pikleはオブジェクトの直列化及び復元。だそうです。jsonと似ています。
jsonとの比較
- jsonの直列化フォーマットは(UTF-8)
- jsonは人間が読める
- jsonはpython以外でも使用できる
だそうです。
前処理の部分
小説には、※や・・・やスペースなど、学習データには不要なものがあるので、
それらを削除する作業をしています。
pythonをwindowsで使用するときのパスに注意
PATH = r"D:\soseki\nekodearu"
FILENAME = r"\nekodearu"の部分ですね。
パスを作りたいフォルダーで右クリックして
「アドレスのコピー」をします。
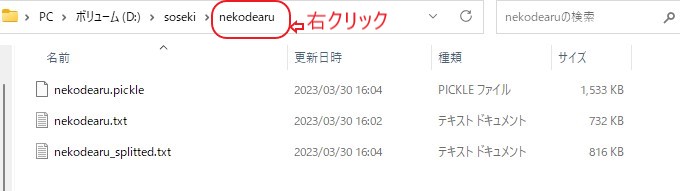
アドレスを「””」で囲んでコードに貼り付ければよいのですが、
windowsの場合は最初に「r」か、「R」をつけます。
なんででしょうね?(笑)
プログラムは、デスクトップでもどこでも好きなところにおいて大丈夫。
エラーが出たら、パスのあたり重点的に見てみてくださいね!
うまくいくと、最初のtxtファイルの場所に、
pickleとsplitted.txtが追加されます。


