
こちら、令和5年3月現在、windowsでのお話です。
MeCab?
エムイーキャブ?ミーキャブ?・・・!めかぶ!だ!・・・
これは形態素解析をするものです。
形態素解析→言語において意味を持つ最小の単位(形態素)に細分化
ざっくりいうと、スペースを空けて単語を分けることです。
例えば、夏目漱石の「こころ」の出だしの文章
私《わたくし》はその人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明けない。
を、こんな感じにします。
私 は その 人 を 常 に 先生 と 呼ん で い た
だ から ここ で も ただ 先生 と 書く だけ で 本名 は 打ち明け ない
全然面白くないですね。でもこうすると、パソコンさんの言語学習に使用できるのです。
インストール
前提として、pythonが入っていてpipが使える状態です。
pipまだだった人は、
python get-pip.pyもう入っている人は最新版へ
pip install --upgrade pipそうしたらmecab-python3をインストールするのですが、
一緒に、UniDicという辞書もインストールします。
pip install mecab-python3pip install unidicこれで終わりかと思いきや、この辞書に中身が入っていない模様。
python -m unidic downloadこれでpythonを起動するとMeCabが使用できる。
隣の客は~~で試してみます。
import MeCab
import unidic
tagger = MeCab.Tagger() # Tagger? タグのことかー!
sample_txt = '隣の客はよく柿食う客だ'
result = tagger.parse(sample_txt) # parse? 解析だそう
print(result)こんな感じになります。
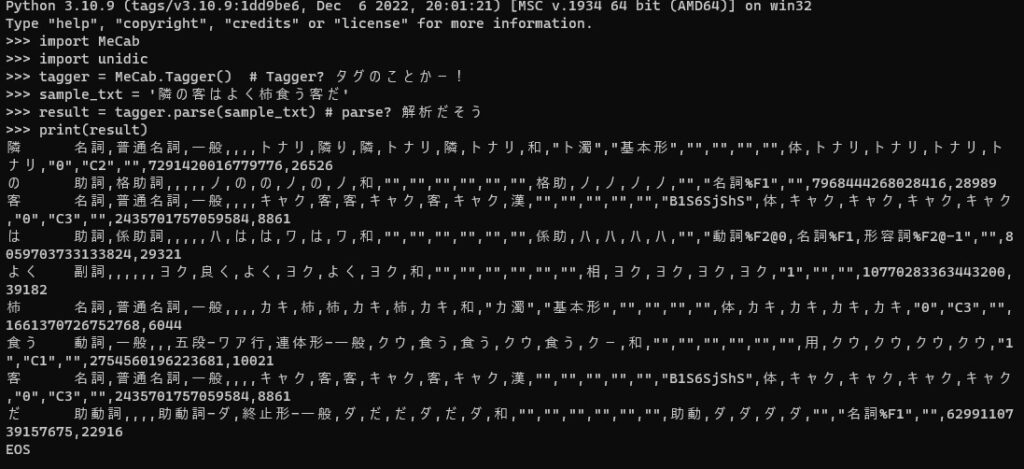
ちなみに、MeCabには出力モードがあるようです。
- mecabrc: (デフォルト)
- -Ochasen: (ChaSen 互換形式)
- -Owakati: (分かち書きのみを出力)
- -Oyomi: (読みのみを出力)がある
こんな感じ。わたし、-0(ゼロ)と打ってしまいましたが、
大文字のOみたいです。(おはずかしい)
使い方は、m = MeCab.Tagger(“-Owakati”)だそうです。
さっきのでやってみます。
import MeCab
import unidic
tagger = MeCab.Tagger("-Owakati") # Tagger? タグのことかー!
sample_txt = '隣の客はよく柿食う客だ'
result = tagger.parse(sample_txt) # parse? 解析だそう
print(result)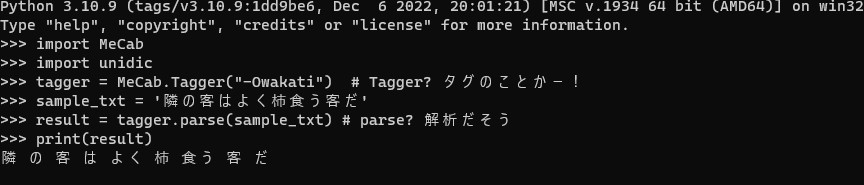
わかちのみを出力しました!
MeCabのパス?
ネットで調べていると、「MeCabのパスを通す必要があります。」とか出てきます。
これ、pythonを立ち上げてMeCabするだけなら関係なくて、
コマンドからいきなりMeCabを起動したい場合必要な設定のようです。
コマンドにmecabと打ちまして、わかちたい文章を入力しますと、
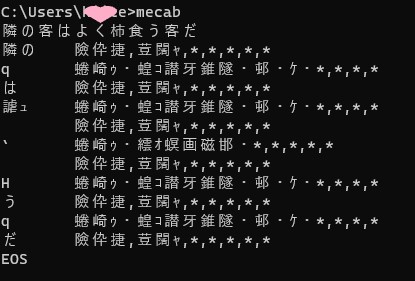
ちょっとした余興ができます。
では、パスを設定しようとするとエラーが出る?
というか、ファイルがない?となります。
このパスを通す「MeCab」は「mecab-python3」のことではありません。
なので、ファイルがなくても納得です。
別途こちらからexeファイルを入手してインストールします。
exeファイルを開けると、いきなり文字コードの設定画面になります。
ここは「UTF-8」にします。
私は、あとはデフォルトでインストールしました。
このインストールフォルダのパスを通すのですね。
パスを通すには、インストール先のフォルダーを見つけておいて、
システムの詳細設定から設定に行けます。
デフォルトのインストール先は、C:\Plogram Files\MeCabです。
パスを通すのは、C:\Program Files\MeCab\binです。
設定は、ウインドウズマーク右クリックで、
システム→システムの詳細設定→環境変数
検索窓に、システムの詳細設定と入力してもよいでしょう。
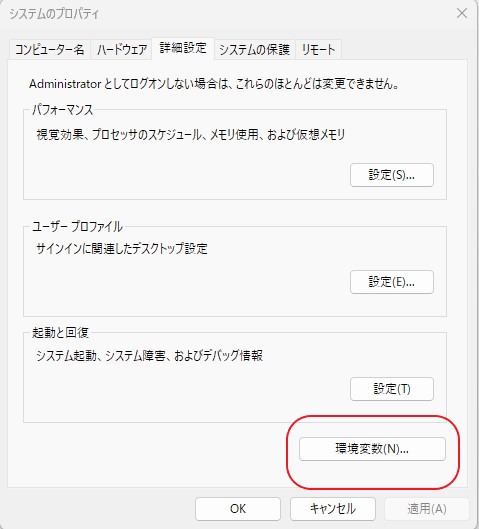
そして、システムの環境変数の「path」がハイライトされた状態で、「編集」をクリック。
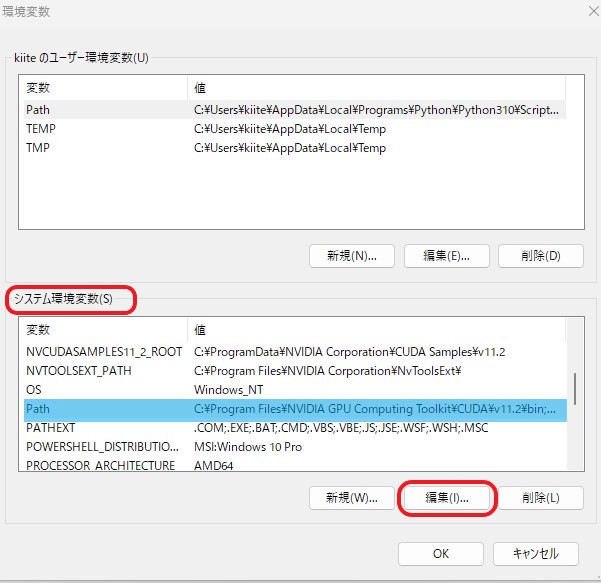
先ほどコピーするといったアドレスを、「新規」で貼り付けます。
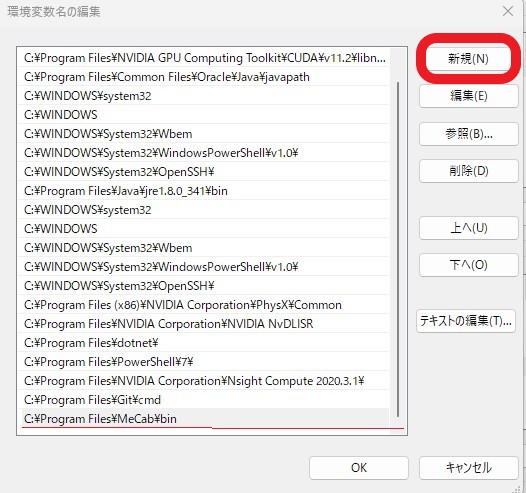
こんな感じにすると、パスが通るようです。

